Can LLMs Predict When We Learn Different Words?

Did you learn the word "glass" before "table"? How about "computer" versus "bus"? And what was your age when you learnt them?
There are some words that people usually learn at a young age, while others are learned later. For example, simpler and less abstract words are usually acquired sooner. This timing is called the age of acquisition (AoA): the typical age when a person learns a word.
AoA estimates are valuable for assessing text readability and adapting content for specific audiences. For example, one can check if the text contains words the target audience is unlikely to know and replace them with synonyms. While English has high-quality AoA datasets, other languages lag behind — including Czech.
So what if we just used language models to guess the typical age of acquisition of Czech words?
[Research conducted as part of IV127 Adaptive Learning Seminar, Masaryk University, Fall 2024]
Preliminary results
Early experiments with Claude showed promising results. The model provided reasonable age estimates whether asked for intervals or specific numbers. It even distinguished between homonyms - predicting that children learn "crown" (royal headpiece) earlier than "crown" (currency).
Existing dataset
The starting point was a dataset compiled by Dan Makalouš, which contains more than 30,000 Czech words with AoA estimations. The estimations are based on various methods, such as foreign datasets, word embeddings, or estimations collected in an experiment. The words are categorized into three confidence levels, reflecting the reliability of their estimation sources:
Category A - highest confidence, 1,311 words.
Category B - 7,635 words
Category C - lowest confidence, 24,008 words.
With most words in categories B and C, language models could potentially improve these lower-confidence estimates.
Model and Prompt Selection
Using Category A words as ground truth, I split the 1,311 high-confidence words into three sets:
Training: 61 words for few-shot examples1
Validation: 250 words for finding the best model/prompt
Test: 1,000 words for final evaluation
I tested mostly two models, Claude 3.5 Sonnet (claude-3-5-sonnet-20240620) and GPT-4o (gpt-4o-2024-08-06), of which Claude performed better. Shortly after the evaluation, the Sonnet was updated, so I also evaluated it (claude-3-5-sonnet-20241022).
The best results came from a simple Czech-language prompt that included few-shot examples but avoided chain-of-thought reasoning2. This approach achieved a mean absolute error (MAE) of 1.58 years on the validation set - significantly better than our baseline linear regression model on the word length and it’s frequency in a corpus (MAE: 2.92).
Analysing the predictions further, we can see that the prediction error resembles a Normal distribution, with the model on average predicting lower age3,
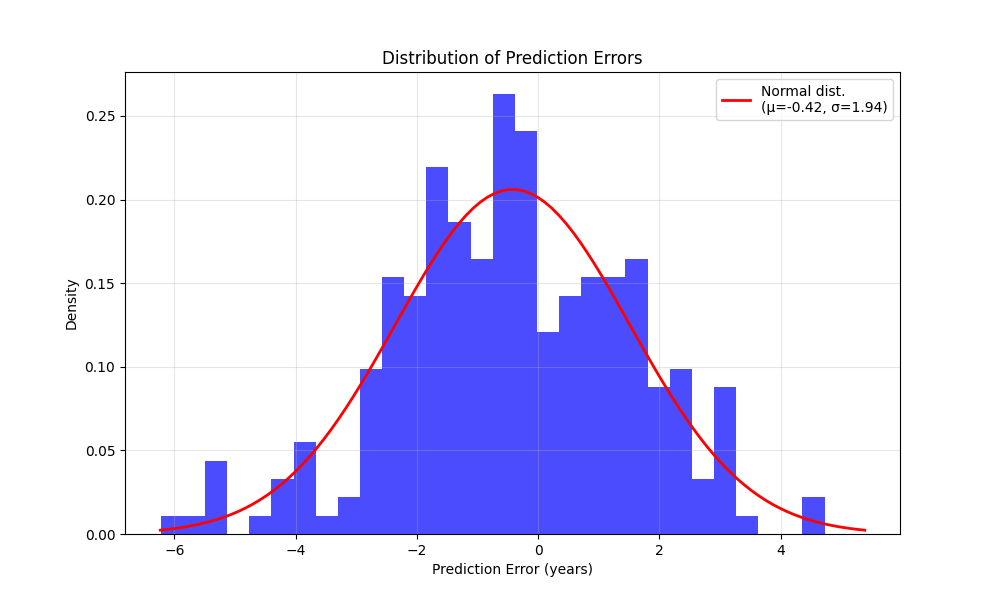
and only ~10% of the words have an error higher than 3 years.
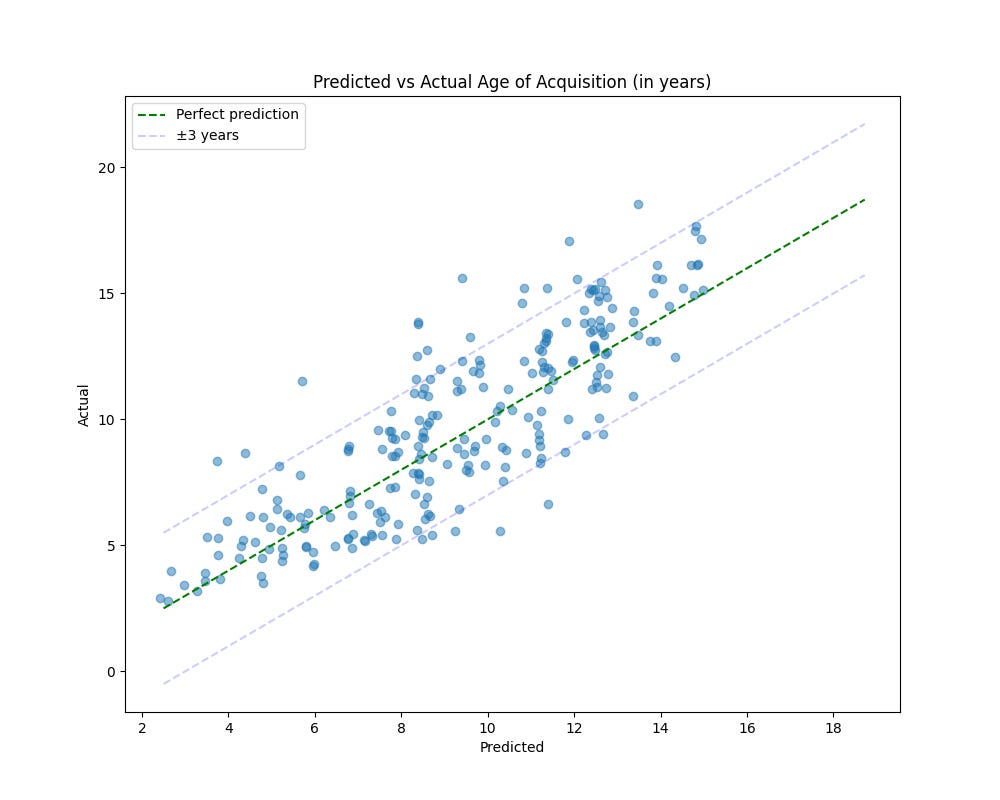
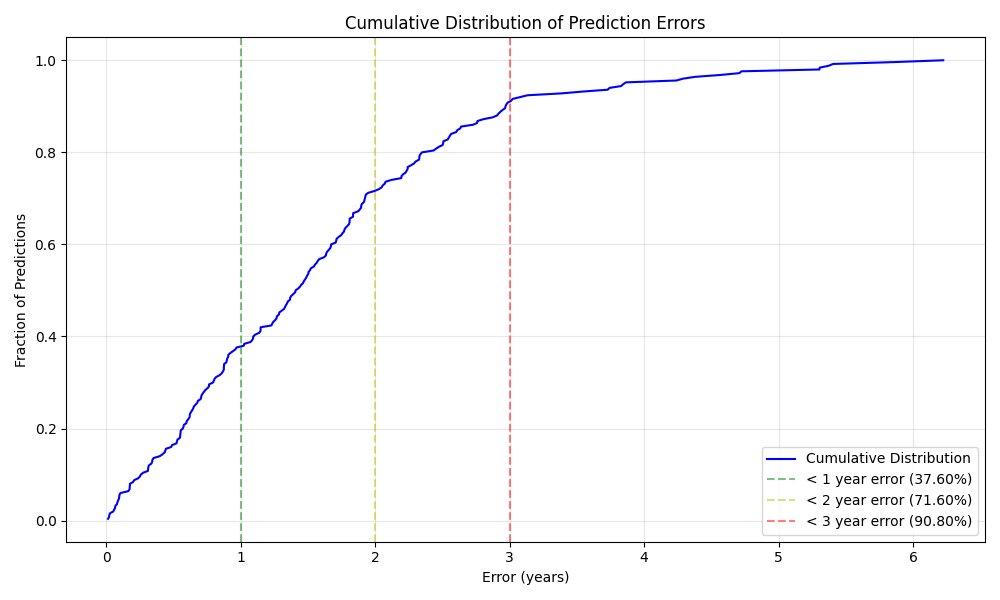
Finally, testing our optimized prompt on the held-out test set yielded an MAE of 1.46 years - slightly better than the validation results. This improvement suggests the prompt does not overfit to the validation data.
Agreement with human annotators
The other group is developing a website where users compare word pairs and select which word they believe children typically learn first. In the end, they collected more than 10,000 comparisons, which we could compare with Claude’s results.
To simulate the pair judgement, Claude’s predictions of the two words are compared, and one with the lower AoA estimation is selected as the word from the pair, which is acquired sooner.
I asked Claude to predict an additional 1250 most frequent words from the comparison dataset for a total of 2500 predictions (including 1250 from the validation and test set). This gave us 2106 comparisons from the dataset for which we had Claude's predictions for both words.
Claude’s judgement agreed with the human judgement in 83.71% of cases. Moreover, when Claude and humans agreed, the predicted age difference between word pairs was larger (median: 3.63 years) than cases of disagreement (median: 1.40 years).
This agreement rate is higher than the one between human judgements and the judgements implied by the estimations from the original dataset, using the same 2500 words, which agree in 75.02% of cases.
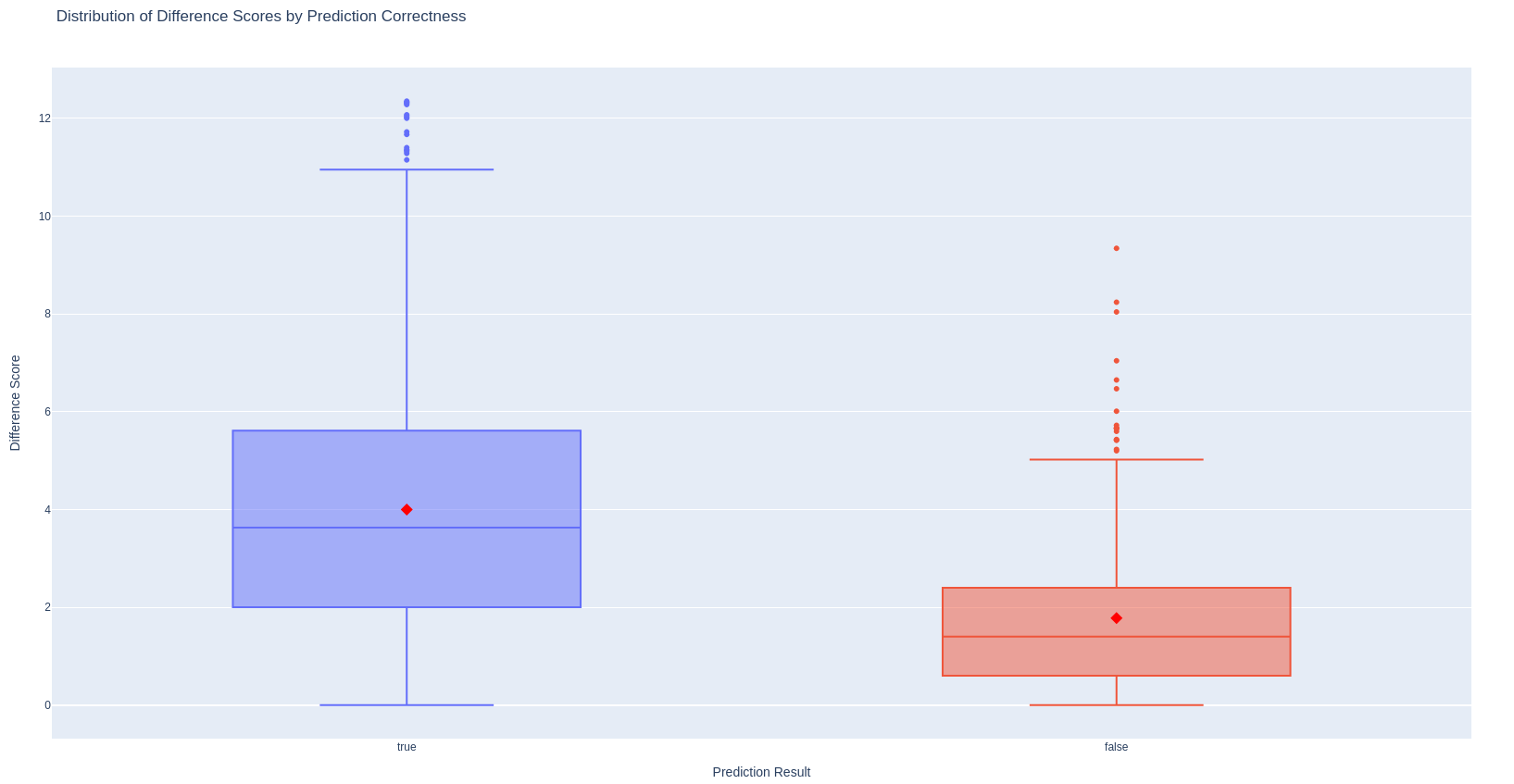
It would be nice to compare this Claude-human agreement rate with the human-human agreement between individual annotators. Unfortunately, we couldn’t do this for two reasons: We did not collect the data to pair the annotator’s identity with the annotations, and most of the compared pairs are in the dataset only once (there are more than 30,000² combinations).
Conclusion
The main goal of this project was to see whether existing AoA estimations can be improved with LLMs. The key challenge was how to evaluate the potential improvement of the predictions.
One proxy pointing to LLM estimations being better is that they agree with human pair judgments 8% more often than the estimations from the original dataset. Of course, these are only preliminary results on a fraction of the dataset. Apart from expanding the dataset, we could also check if Claude agrees with humans even more often than the original predictions if only words from B and/or C categories are considered.
These results suggest LLM-based estimates are at least comparable to traditionally compiled datasets and potentially even better. This is interesting especially when comparing the effort required between the two methods: creating the dataset required a lot of work to compile different sources, here we only need a well-crafted prompt.
Of course, these experiments would not be possible without the original dataset! However, they suggest that LLMs may be used to expand AoA estimates for Czech and other languages lacking accurate datasets.
Only fixed 30 were used in the few-shot prompt for efficiency.
Full prompt:
Vytvořte odhad věku osvojení (Age of Acquisition, AoA) pro české slovo, které vám bude předloženo.
Váš výstup by měl obsahovat pouze číslo s desetinnou čárkou (přesnost na jedno až dvě desetinná místa) představující věk v letech, kdy se typické české dítě naučí dané slovo. Číslo uveďte ve značkách <estimation>.
České slovo k analýze je uvedeno ve značkách <czech_word>.
Příklady:
"vlastní": 6.53
"rychle": 3.96
"normální": 6.82
"severní": 7.91
"zbývat": 4.32
"jev": 9.05
"obtížný": 7.28
"tudíž": 9.47
"výpočet": 7.39
"šílený": 5.08
"potrestat": 4.42
"uznání": 8.67
"extrémně": 9.69
"geologický": 12.84
"rodák": 9.86
"poprosit": 4.01
"rodičovský": 7.94
"prodejní": 7.00
"závisle": 11.00
"elektroda": 11.86
"smysluplný": 8.87
"stotisíc": 8.20
"polykat": 5.51
"třídění": 7.74
"zvyšující": 10.12
"oštěp": 9.35
"zapsaný": 7.16
"didaktika": 13.96
"citelně": 11.17
"starověk": 10.87
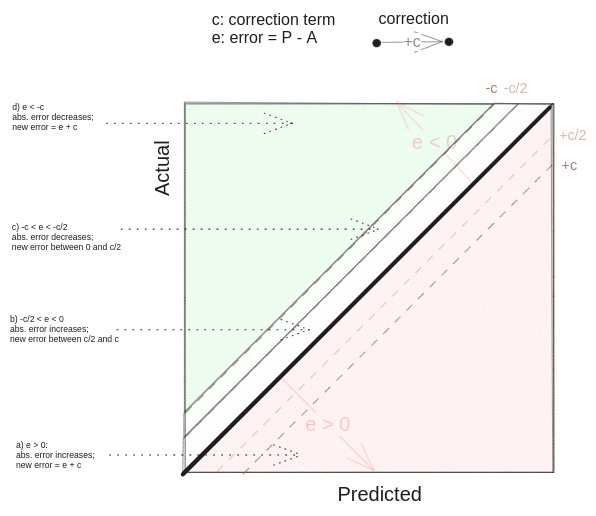
<czech_word>matka</czech_word>A straightforward way to correct this would be to add this value to the model’s prediction. However, this did not help as much as I expected! On the validation set, adding a correction term c=0.42 to each prediction improved the MAE to 1.53, which is only 0.05 improvement.
Thinking about it further, a simple mean error doesn’t tell us how much the correction will improve. We also need there to be more underpredictions than overpredictions, otherwise improving underpredictions is cancelled by degrading overpredictions.
Moreover, applying the correction even if the underprediction is bigger than -c/2 worsens the absolute error — if the error (prediction - actual) is -0.2, after correcting the prediction, it becomes 0.22, which is even bigger! See the visualization of the different cases below.